Inside PostgreSQL. mvcc, wal, toast, vacuum
Here, I would like to describe basic concepts or elements that exist in PostgreSQL and are its main parts.
Book to read: PostgreSQL 14 изнутри, Егор Рогов
MVCC
MVCC - Multiversion Concurrency Control
The main idea - read locks don't affects other read or write locks. Two different transactions can lock the same data and read and write this data at the same time.
With MVCC we can avoid table or row loks and increase performance.
Transaction isolation
In PostgreSQL we can use
READ COMMITTEDREPEATABLE READ(without phantom reading)SERIALIZABLE
Note: READ UNCOMMITED can be used but works in PostgreSQL like READ COMMITTED
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
-- or
BEGIN TRANSACTION ISOLATION LEVEL REPEATABLE READ;
default isolation level : READ COMMITTED
TOAST
TOAST - the Oversized-Attribute Storage Technique
Page size in PostgreSQL equals 8 kB and one tuple can't be splitted into more than one page. To store large tuples it's data will be compressed or splitted into pages using a mechanism named TOAST.
TOAST - it's a separate table with sliced column values from the original table.
problems
TOAST adds performance penalty for TEXT, JSONB data structures.
It means, it is bad idea to use data from json (jsonb) fields directly in OLTP mode.
something to read "Борьба с TOAST или будущее JSONB в PostgreSQL"
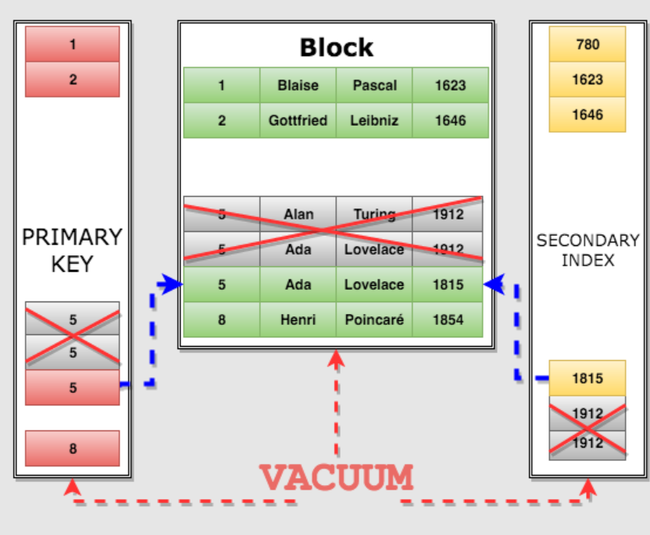
VACUUM
VACUUM reclaims storage occupied by dead tuples.
'dead tuples' means tuples that were marked as unavailable during the deletion or update process and that not in transaction scope.
VACUUM my_table;
autovacuum - the process that clears the table
WAL
WAL - Write Ahead Log
This is a fast storage for changes (in cached pages in RAM) which will be saved to disk before the transaction is approved.
The main idea - we can avoid data loss with pages which are cached in memory and still not saved to disk.
Data file
Table data (and some other) in PostgreSQL are splitted in 8 kB pages and stored in format:
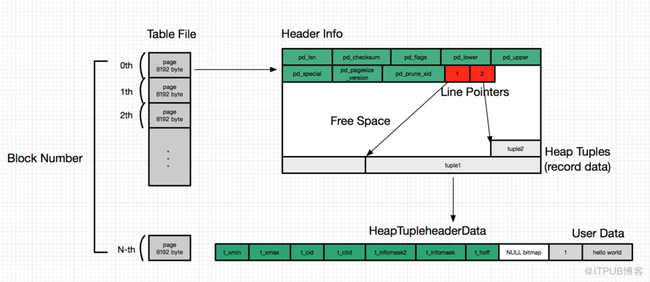
- When we need to read one tuple or one value, we must read whole page.
- When we need to read value for one single column, we must read all data from all columns.
Conclusion
Interesting to know 🙂