Хранение свойств растений без схемы
В этой статье описано почему реляционная схема для хранения свойств растений оказалась не такой уж и удобной и как ее можно улучшить.
Проблемы реляционной схемы?
Проблема, собственно, со схемой. Ниже на схеме представлена предыдущая версия, которая была описана в Seed storage model
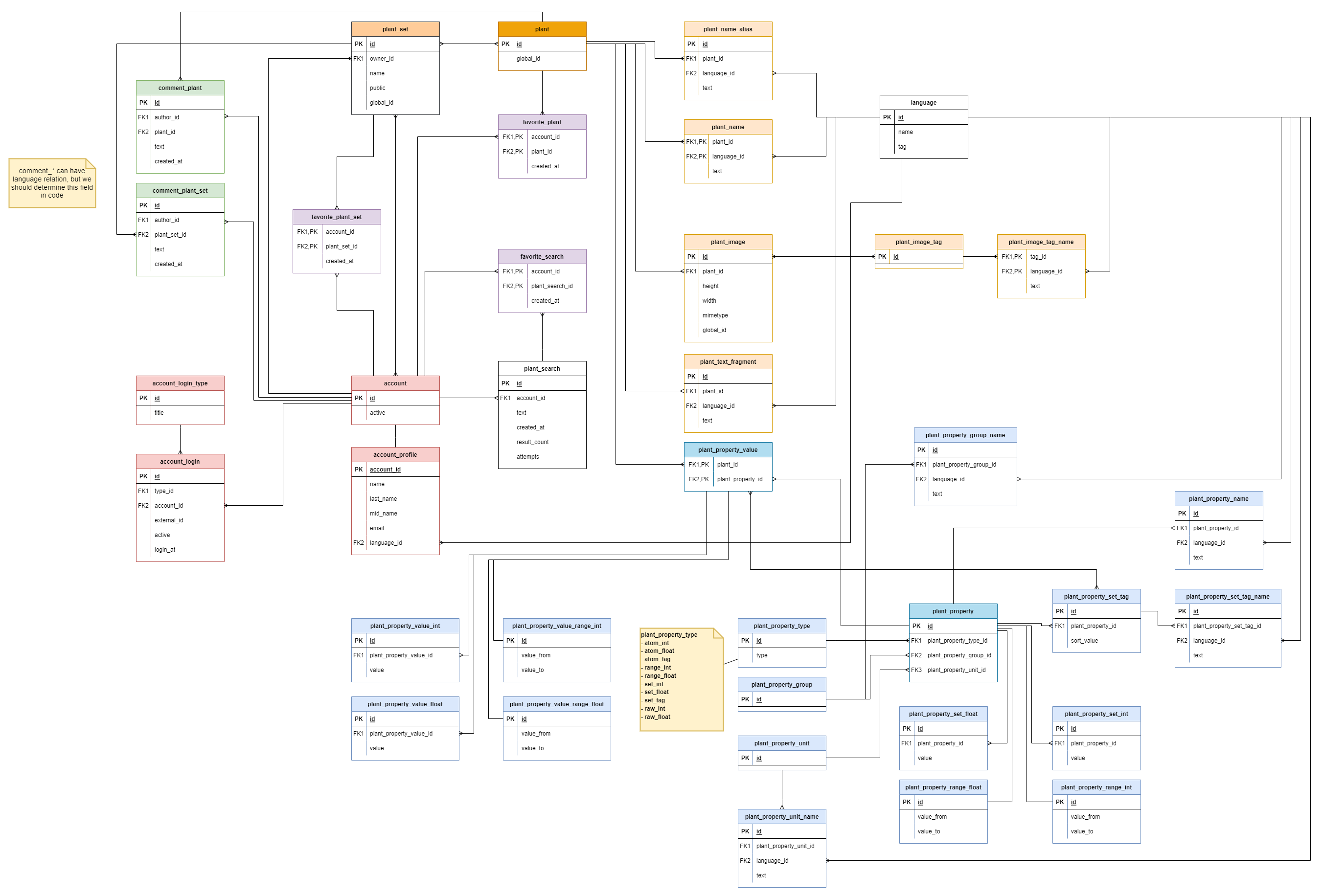
sql для создания схемы (github)
В этой версии свойства растений были разложены на множество табличек что сделало ее очень тяжёлой и совсем нем понятной.
Свойства растений размазаны по табличкам из-за того, что значения растений имеют сильно разную структуру, набор значений и их типы этих значений.
Пример того, что мы должны предоставить клиентам:
{
"plantId": "...",
"properties": [
{"type": "color", "value": "green"},
{"type": "perennial", "value": true},
{"type": "max_height", "value": 3.3, "units": "metre"},
{"type": "flowering_period", "from": 5, "to": 6, "units": "month"}
]
}
В результате, чтобы использовать данные нам нужно держать в голове все таблицы свойств и связи, что довольно не просто. Даже наличие документации не дает возможности быстро внести изменения в эту структуру или просто понять, как все работает. Код получается довольно сильно привязан к структуре данных что вызывает множество изменений при доработке схемы.
Хранилище без схемы
Для упрощения кода и упрощения структуры мы можем реализовать схему, которая основана на JSON и не имеет строгой структуры в базе данных.
Несмотря на то, что JSON будет без схемы, мы можем использовать constraints для предоставления гарантий консистентности данных.
Для хранения свойств будем использовать такую схему:
CREATE TABLE IF NOT EXISTS plant_properties (
id UUID NOT NULL PRIMARY KEY,
plant_id UUID NOT NULL,
property jsonb NOT NULL
);
INSERT INTO plant_properties (id, plant_id, property) VALUES
(uuid_generate_v4(), 'a03a347f-8435-4caa-aeee-3eaaa38983ba', '{"type": "color", "value": "green"}'),
(uuid_generate_v4(), 'a03a347f-8435-4caa-aeee-3eaaa38983ba', '{"type": "perennial", "value": true}'),
(uuid_generate_v4(), 'a03a347f-8435-4caa-aeee-3eaaa38983ba', '{"type": "max_height", "value": 1.1, "units": "metre"}'),
(uuid_generate_v4(), 'a03a347f-8435-4caa-aeee-3eaaa38983ba', '{"type": "flowering_period", "from": 5, "to": 6, "units": "month"}')
;
В такой схеме мы сможем:
- максимально изолировать код, который специфичен для конкретного типа свойств
- упростить понимание того, как хранятся данные в DB
- гарантировать консистентность данных на столько на сколько это возможно с JSON
Есть альтернативный вариант хранения JSON, и он мне не нравится
CREATE TABLE IF NOT EXISTS plant_properties (
plant_id UUID NOT NULL PRIMARY KEY,
payload jsonb NOT NULL
);
Не нравится мне это решение:
- поле payload будет расти со временем
- любое обновление payload вызывает блокировку всех свойств растения
- чтение одного свойства приводит к чтению всех свойств растения
В результате схема с JSON, где одна запись - это одно свойство, выглядит более привлекательным и надежной, хотя и немного усложняет чтение всех свойств одного растения.
Новая схема для свойств растений
DROP INDEX IF EXISTS property_json_idx;
DROP TABLE IF EXISTS plant_properties;
DROP TABLE IF EXISTS property_type;
DROP TABLE IF EXISTS property_group;
DROP TABLE IF EXISTS pool_names;
CREATE TABLE IF NOT EXISTS pool_names
(
id uuid NOT NULL,
ru character(255),
en character(255),
CONSTRAINT pool_names_pkey PRIMARY KEY (id),
CONSTRAINT any_name_must_exists CHECK (
ru IS NOT NULL AND char_length(ru) > 0 OR
en IS NOT NULL AND char_length(en) > 0
)
)
CREATE TABLE IF NOT EXISTS property_group
(
id uuid NOT NULL,
name_id uuid NOT NULL,
CONSTRAINT property_group_pkey PRIMARY KEY (id),
CONSTRAINT property_group_name_id_fkey FOREIGN KEY (name_id)
REFERENCES pool_names (id)
)
CREATE TABLE IF NOT EXISTS property_type
(
id uuid NOT NULL,
name_id uuid NOT NULL,
group_id uuid,
details jsonb NOT NULL,
type_details_json_schema text,
property_json_schema text,
CONSTRAINT property_type_pkey PRIMARY KEY (id),
CONSTRAINT property_type_group_id_fkey FOREIGN KEY (group_id)
REFERENCES property_group (id),
CONSTRAINT property_type_name_id_fkey FOREIGN KEY (name_id)
REFERENCES pool_names (id)
)
CREATE TABLE IF NOT EXISTS plant_properties
(
id uuid NOT NULL,
plant_id uuid NOT NULL,
property_type_id uuid NOT NULL,
property jsonb NOT NULL,
CONSTRAINT plant_properties_pkey PRIMARY KEY (id),
CONSTRAINT plant_properties_property_type_id_fkey FOREIGN KEY (property_type_id)
REFERENCES property_type (id),
CONSTRAINT type_must_exists CHECK (
(property -> 'type_id') IS NOT NULL
),
CONSTRAINT type_is_string CHECK (
jsonb_typeof(property -> 'type_id') = 'string'
),
CONSTRAINT type_same_as_in_table CHECK (
property_type_id = ((property ->> 'type_id')::uuid)
),
-- CONSTRAINT property_validation CHECK (
-- jsonb_typeof(property -> 'min_value') = 'number' AND
-- jsonb_typeof(property -> 'max_value') = 'number' AND
-- (property -> 'max_value') >= (property -> 'min_value')
-- )
)
CREATE INDEX IF NOT EXISTS property_json_idx
ON plant_properties
USING gin (property jsonb_path_ops);